Building LLMs-Powered Apps with OPL Stack
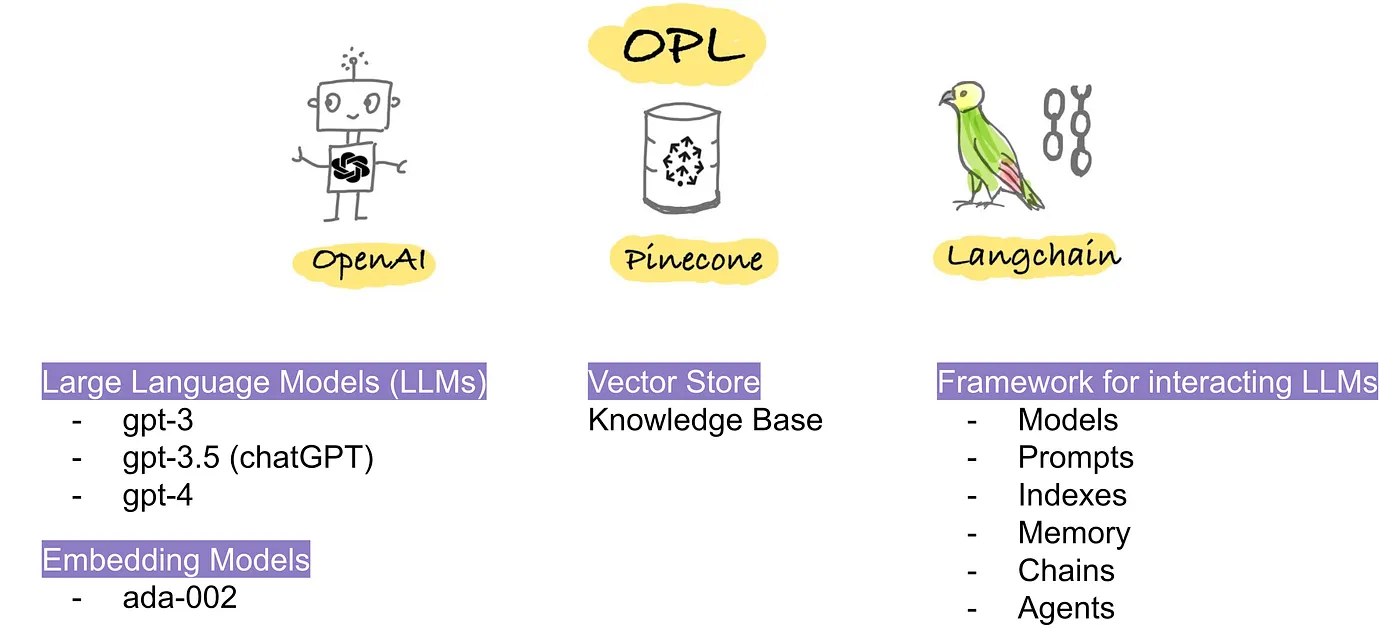
OPL stands for OpenAI, Pinecone, and Langchain
OpenAI:
- 強力なLLM(例:chatGPTとgpt-4)へのAPIアクセスを提供します。
- テキストを埋め込みに変換するための埋め込みモデルを提供します。
Pinecone:
- 埋め込みベクトルの保存、意味的類似性の比較、高速な検索を提供します。
Langchain:
- 6つのモジュール(モデル、プロンプト、インデックス、メモリ、チェーン、エージェント)から構成されています。
- モデルは埋め込みモデル、チャットモデル、LLMなどの柔軟性を提供します。これにはOpenAIの提供するものに限らず、Hugging FaceのBLOOMやFLAN-T5などの他のモデルも使用できます。
- メモリ:チャットボットが過去の会話を記憶するためのさまざまな方法があります。私の経験から言うと、エンティティメモリはうまく動作し効率的です。
- チェーン:Langchainに初めて触れる場合、チェーンは素晴らしい出発点です。ユーザーの入力を処理し、LLMモデルを選択し、プロンプトテンプレートを適用し、知識ベースから関連するコンテキストを検索するためのパイプラインのような構造を持っています。
開発プロセスには3つの主要なステップがあります:
ステップ1:Pineconeで外部の知識ベースを構築する
ステップ2:質問応答サービスにLangchainを使用する
ステップ3:Streamlitでアプリを構築する
その他のメモ:
Split the contentin to smaller chunks using Langchain's RecursiveCharacterTextSplitter. The basic idea is to first split by the paragraph, then split by sentence, with overlapping (20 tokens). This helps preserve meaningful information and context from the surrounding sentences.

The user asks a question: "What are the best running shoes in 2023?".
The question is converted into embedding using the ada-002model.
The user question embedding is compared with all vectors stored in Pinecone using similarity_searchfunction, which retrieves the top 3 text chunks that are most likely to answer the question.
Langchain then passes the top 3 text chunks as context , along with the user question to gpt-3.5 ( ChatCompletion ) to generate the answers.
Comments