RAGは本当に熱い。会社で検証環境を提供したら使いたい要望が殺到している。ある部門の試算では年間10数億円の利益貢献。これでちゃんとPJ化しないね。
ただ体系的に検索品質を評価するためにどうすれば良いのか課題なのでこちらを参考になった。
Best Practices for LLM Evaluation of RAG Applications
長い文章のため、ChatGPTで下記Promptで訳してもらった:
「あなたはプロの日英翻訳専門家。質問者に質問して、質問者からの英語を日本語に訳してください。翻訳のプロセスは2段階でお願いします。まず直訳して、それから直訳の結果に対して、ネイティブ日本語者から見ても自然な日本語に再度訳直してください。」
---
チャットボットは、大規模な言語モデル(LLM)の強力なチャットと推論能力を活用するための最も普及したユースケースです。
Retrieval augmented generation (RAG) アーキテクチャは、ナレッジベース(ベクトルストアを介した)の利点と生成モデル(例:GPT-3.5およびGPT-4)を組み合わせることで、幻覚を減らし、最新の情報を維持し、特定のドメインの知識を活用するための業界標準となりつつあります。
しかし、チャットボットの応答の品質を評価することは今日も未解決の問題です。
業界標準が定義されていないため、組織は人間による評価(ラベリング)に頼る必要がありますが、これは時間がかかり、スケーリングが難しいです。
私たちは、実践に理論を適用して、LLMの自動評価のベストプラクティスを形成し、RAGアプリケーションを迅速かつ自信を持ってプロダクションに展開できるよう支援しました。
このブログは、Databricksで実施している一連の調査の最初を表しており、LLMの評価に関する学びを提供することを目指しています。
この投稿でのすべての研究は、Databricksのシニアソフトウェアエンジニアであり、Databricks Documentation AI Assistantの作成者であるQuinn Lengによって実施されました。
実践での自動評価に関する課題
最近、LLMコミュニティでは、「LLMを判定者」として使用する自動評価の可能性を探っており、多くの人が、GPT-4などの強力なLLMを使用して、LLMの出力を評価しています。
lmsysグループの研究論文は、ライティング、数学、世界知識のタスクにおいて、さまざまなLLM(GPT-4、ClaudeV1、GPT-3.5)を判定者として使用することの実現可能性や利点/欠点を探るものです。
この素晴らしい研究にもかかわらず、実践でLLM判定者をどのように適用するかに関して、まだ多くの未解決の問題があります。
RAGアプリケーションに効果的な自動評価を適用する
私たちは、上記の質問について、Databricksの独自のチャットボットアプリケーションのコンテキストで可能なオプションを探求しました。
私たちは、私たちの調査結果が一般的であり、したがって、費用を抑え、迅速なスピードでRAGベースのチャットボットを効果的に評価するために、あなたのチームに役立つと考えています。
私たちの調査に基づき、LLM判定者を使用する際には、次の手順を推奨します:
1. 1-5の採点尺度を使用する
2. 採点ルールを理解するために、GPT-4を例なしでLLM判定者として使用する
3. 採点スコアごとに1つの例を持つように、LLM判定者をGPT-3.5に切り替える
ベストプラクティスを確立するための当社の方法論
この投稿の残りの部分では、これらのベストプラクティスを形成するために実施した一連の実験を説明します。
実験のセットアップ

実験は3つのステップで行われました。
1. 評価データセットの生成:
私たちは、Databricksのドキュメントから100個の質問と文脈のデータセットを作成しました。文脈は、質問に関連するドキュメント(またはその一部)を表します。

2. 回答シートの生成:
評価データセットを使用して、異なる言語モデルに対して回答を生成し、質問-文脈-回答のペアを「回答シート」と呼ばれるデータセットに保存しました。
この調査では、GPT-4、GPT-3.5、Claude-v1、Llama2-70b-chat、Vicuna-33b、mpt-30b-chatを使用しました。
3. 成績の生成:
回答シートを元に、さまざまなLLMを使用して成績とその成績の理由を生成しました。
成績は、正確性(重み付け:60%)、包括性(重み付け:20%)、読みやすさ(重み付け:20%)の合成スコアです。
この重み付けスキームを選択した理由は、生成された回答の正確性に対する私たちの優先順位を反映するためです。
他のアプリケーションでは、これらの重み付けを異なるように調整することができますが、私たちは正確性が主要な要因であることを期待しています。
さらに、以下の技術が使用されて、位置バイアスを回避し、信頼性を向上させました:
実験1:人間の採点との整合性
人間の注釈者とLLM判定者との間の一致レベルを確認するために、gpt-3.5-turboおよびvicuna-33bからの回答シート(採点尺度0-3)をラベリング会社に送信して人間のラベルを収集し、その結果をGPT-4の採点出力と比較しました。
以下が結果です:
人間とGPT-4の判定者は、正確性と読みやすさのスコアに関して80%以上の一致を得ることができます。スコアの差が1以下であるという要件を満たす場合、一致レベルは95%以上に達することができます。
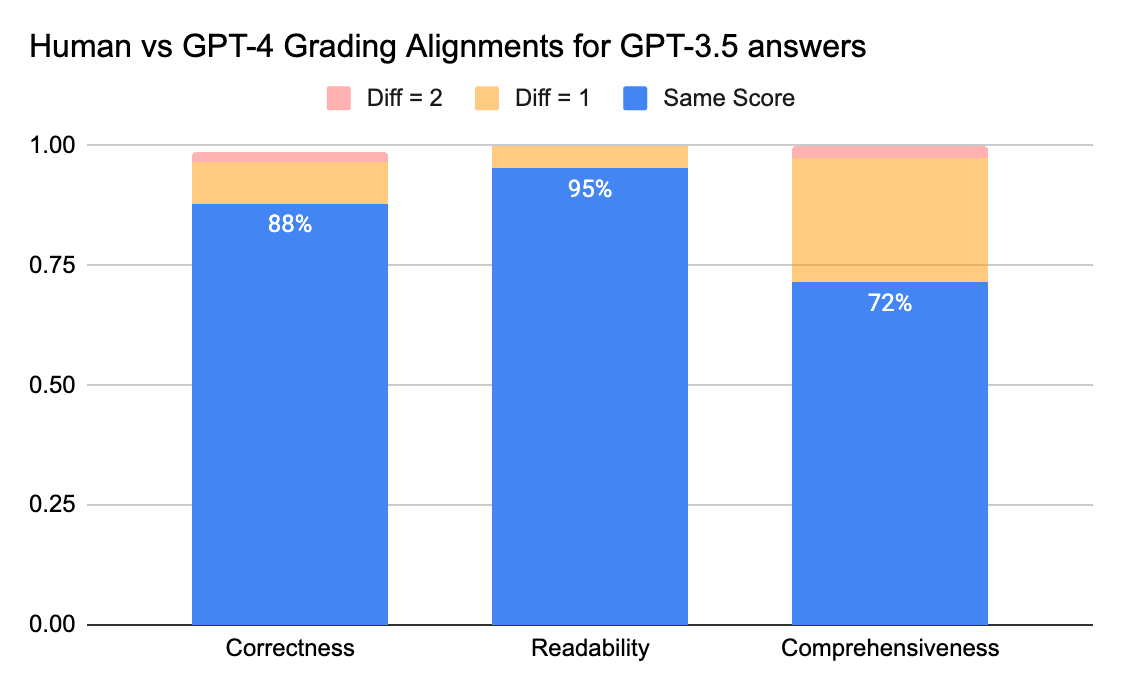
包括性のメトリックは、正確性や読みやすさなどのメトリックよりも「包括的」という言葉が主観的であるというビジネスステークホルダーからのフィードバックと一致しています。
実験2:例による精度
lmsysの論文は、このプロンプトを使用して、LLM判定者に回答の役立ち度、関連性、正確さ、深さ、創造性、詳細度に基づいて評価するように指示します。
しかし、論文では採点基準の具体的な詳細は共有されていません。
私たちの調査から、多くの要因が最終的なスコアに大きく影響することがわかりました。例えば:
私たちは、以下のような方法を試して、指定された採点尺度のためのLLM判定者に指示するための基準を開発しました:
1. 元のプロンプト:
以下は、lmsysの論文で使用された元のプロンプトです:
Please act as an impartial judge and evaluate the quality of the response provided by an AI assistant to the user question displayed below. Your evaluation should consider factors such as the helpfulness, relevance, accuracy, depth, creativity, and level of detail of the response. Begin your evaluation by providing a short explanation. Be as objective as possible. After providing your explanation, you must rate the response on a scale of 1 to 10 by strictly following this format
公平な裁判官として、以下に表示されるユーザーの質問に対する AI アシスタントの応答の質を評価してください。評価では、応答の有用性、関連性、正確性、深さ、創造性、詳細レベルなどの要素を考慮する必要があります。短い説明を入力して評価を開始します。できるだけ客観的になってください。説明を行った後、この形式に厳密に従って、回答を 1 から 10 のスケールで評価する必要があります。
元のlmsys論文のプロンプトを修正して、正確さ、包括性、可読性に関する私たちの指標を出力するようにし、また、各スコアの前に判定者に1行の正当化を提供するよう促しました(chain-of-thoughtを活用するため)。
以下は、例を提供しないzero-shotバージョンのプロンプトと、各スコアに1つの例を提供するfew-shotバージョンのプロンプトです。
それから、同じ回答用紙を入力として使用し、両方のプロンプトタイプからの評定結果を比較しました。
2. Zero shot学習:
LLMの判定者に、正確さ、包括性、可読性に関する私たちの指標を出力するよう要求し、また、各スコアに1行の正当化を提供するよう促します。
Please act as an impartial judge and evaluate the quality of the provided answer which attempts to answer the provided question based on a provided context.
You'll be given a function grading_function which you'll call for each provided context, question and answer to submit your reasoning and score for the correctness, comprehensiveness and readability of the answer.
公平な裁判官として行動し、提供されたコンテキストに基づいて提供された質問に回答しようとする、提供された回答の質を評価してください。
与えられた関数 grading_function を、提供されたコンテキスト、質問、回答ごとに呼び出して、推論と回答の正確さ、包括性、読みやすさのスコアを送信します。
3. Few Shots 学習:
私たちはZero shotのプロンプトを適応して、スケール内の各スコアについて明示的な例を提供するようにしました。新しいプロンプト:
Please act as an impartial judge and evaluate the quality of the provided answer which attempts to answer the provided question based on a provided context.You'll be given a function grading_function which you'll call for each provided context, question and answer to submit your reasoning and score for the correctness, comprehensiveness and readability of the answer.
Below is your grading rubric:
- Correctness: If the answer correctly answer the question, below are the details for different scores:
- Score 0: the answer is completely incorrect, doesn't mention anything about the question or is completely contrary to the correct answer.
- For example, when asked "How to terminate a databricks cluster", the answer is empty string, or content that's completely irrelevant, or sorry I don't know the answer.
- Score 1: the answer provides some relevance to the question and answers one aspect of the question correctly.
- Example:
- Question: How to terminate a databricks cluster
- Answer: Databricks cluster is a cloud-based computing environment that allows users to process big data and run distributed data processing tasks efficiently.
- Or answer: In the Databricks workspace, navigate to the "Clusters" tab. And then this is a hard question that I need to think more about it
- Score 2: the answer mostly answer the question but is missing or hallucinating on one critical aspect.
- Example:
- Question: How to terminate a databricks cluster"
- Answer: "In the Databricks workspace, navigate to the "Clusters" tab.
Find the cluster you want to terminate from the list of active clusters.
And then you'll find a button to terminate all clusters at once"
- Score 3: the answer correctly answer the question and not missing any major aspect
- Example:
- Question: How to terminate a databricks cluster
- Answer: In the Databricks workspace, navigate to the "Clusters" tab.
Find the cluster you want to terminate from the list of active clusters.
Click on the down-arrow next to the cluster name to open the cluster details.
Click on the "Terminate" button. A confirmation dialog will appear. Click "Terminate" again to confirm the action."
- Comprehensiveness: How comprehensive is the answer, does it fully answer all aspects of the question and provide comprehensive explanation and other necessary information. Below are the details for different scores:
- Score 0: typically if the answer is completely incorrect, then the comprehensiveness is also zero score.
- Score 1: if the answer is correct but too short to fully answer the question, then we can give score 1 for comprehensiveness.
- Example:
- Question: How to use databricks API to create a cluster?
- Answer: First, you will need a Databricks access token with the appropriate permissions. You can generate this token through the Databricks UI under the 'User Settings' option. And then (the rest is missing)
- Score 2: the answer is correct and roughly answer the main aspects of the question, but it's missing description about details. Or is completely missing details about one minor aspect.
- Example:
- Question: How to use databricks API to create a cluster?
- Answer: You will need a Databricks access token with the appropriate permissions. Then you'll need to set up the request URL, then you can make the HTTP Request. Then you can handle the request response.
- Example:
- Question: How to use databricks API to create a cluster?
- Answer: You will need a Databricks access token with the appropriate permissions. Then you'll need to set up the request URL, then you can make the HTTP Request. Then you can handle the request response.
- Score 3: the answer is correct, and covers all the main aspects of the question
- Readability: How readable is the answer, does it have redundant information or incomplete information that hurts the readability of the answer.
- Score 0: the answer is completely unreadable, e.g. fully of symbols that's hard to read; e.g. keeps repeating the words that it's very hard to understand the meaning of the paragraph. No meaningful information can be extracted from the answer.
- Score 1: the answer is slightly readable, there are irrelevant symbols or repeated words, but it can roughly form a meaningful sentence that cover some aspects of the answer.
- Example:
- Question: How to use databricks API to create a cluster?
- Answer: You you you you you you will need a Databricks access token with the appropriate permissions. And then then you'll need to set up the request URL, then you can make the HTTP Request. Then Then Then Then Then Then Then Then Then
- Score 2: the answer is correct and mostly readable, but there is one obvious piece that's affecting the readability (mentioning of irrelevant pieces, repeated words)
- Example:
- Question: How to terminate a databricks cluster
- Answer: In the Databricks workspace, navigate to the "Clusters" tab.
Find the cluster you want to terminate from the list of active clusters.
Click on the down-arrow next to the cluster name to open the cluster details.
Click on the "Terminate" button.........................................
A confirmation dialog will appear. Click "Terminate" again to confirm the action.
- Score 3: the answer is correct and reader friendly, no obvious piece that affect readability.
- Then final rating:
- Ratio: 60% correctness + 20% comprehensiveness + 20% readability
この実験から、いくつかのことを学びました:
1. GPT-4を使用してFew Shotsのプロンプトを使うことは、結果の一貫性に明らかな違いをもたらしませんでした。
詳細な採点基準と例を含めた場合、異なるLLMモデル間でGPT-4の採点結果に顕著な改善が見られませんでした。
興味深いことに、スコアの範囲にわずかな変動を引き起こしました。


2. GPT-3.5-turbo-16kに数例を含めると、スコアの一貫性が大幅に向上し、結果が利用可能になります。
詳細な採点基準や例を含めると、GPT-3.5の採点結果に非常に明白な改善が見られます(右側のチャート)。
実際の平均スコア値はGPT-4とGPT-3.5でわずかに異なります(スコア3.0対スコア2.6)、しかし、順位と精度はかなり一貫しています。
3. 逆に、(左側のスクリーンショット)採点基準なしでGPT-3.5を使用すると、非常に一貫性のない結果が得られ、完全に使用できません。
4. プロンプトが4kトークンを超える場合、GPT-3.5-turboではなく、GPT-3.5-turbo-16kを使用していることに注意してください。


実験3:適切な評価尺度
LLMを判定者として使用する論文では、採点尺度に非整数の0〜10スケール(つまり、浮動小数点数)を使用しています。言い換えれば、最終スコアのために高精度の採点基準を使用しています。これらの高精度の尺度は、以下の問題を引き起こします:
私たちは、「最良」とされる尺度に関するガイダンスを提供するために、さまざまな低精度の採点尺度を実験しました。最終的に、整数尺度の0〜3または0〜4(Likert尺度に固執したい場合)を推奨します。
0〜10、1〜5、0〜3、および0〜1の尺度を試しましたが、次のことを学びました:


上記のプロットに示されているように、GPT-4とGPT-3.5の両方が、異なる低精度の採点尺度を使用して結果の一貫した順位付けを維持できるため、0〜3や1〜5などの低い採点尺度を使用することで、精度と説明可能性をバランスさせることができます。
したがって、人間のラベルと合わせやすく、採点基準を理解しやすく、範囲内の各スコアについて例を提供するために、0-3または1-5を採点尺度として推奨します。
実験4:使用事例間の適用性
LLM-as-judge として使用する論文は、LLMと人間の判断の両方がVicuna-13BモデルをGPT-3.5のほぼ同等の競合相手としてランク付けすることを示しています。

(図は、LLM-as-judgeとして使用する論文の図4から取得されています:https://arxiv.org/pdf/2306.05685.pdf)
しかし、私たちは文書のQ&A使用事例の一連のモデルをベンチマークしたところ、はるかに大きなVicuna-33Bモデルでも、文脈に基づいて質問に答える際にはGPT-3.5よりも明らかに性能が劣ることがわかりました。
これらの結果は、GPT-4、GPT-3.5、および人間の判定者(実験1で述べられているように)によっても確認されており、Vicuna-33BがGPT-3.5よりも性能が劣っているということに全員同意しています。
私たちは、論文で提案されたベンチマークデータセットをより詳しく調査しましたが、3つのカテゴリのタスク(執筆、数学、知識)は、文脈に基づいた回答の合成能力に直接的に反映されたり貢献したりしませんでした。代わりに、直感的には、文書のQ&A使用事例には読解力と指示の遵守に関するベンチマークが必要です。
したがって、評価結果は使用事例間で転送できず、顧客のニーズにどれだけ適合するかを適切に評価するためには、使用事例固有のベンチマークを構築する必要があります。
Comments