Corrective Retrieval Augmented Generation
Abstract
大規模言語モデル(LLM)は、生成されるテキストの正確性を完全に確保することができないため、必然的に幻覚を示します。(情報を取り込んでいるパラメータの知識だけでは。)
検索補強型生成(RAG)はLLMを補完する実用的な手段ですが、取得されたドキュメントの関連性に大きく依存しており、検索が誤った場合にモデルがどのように振る舞うかという懸念があります。
このため、私たちは生成の堅牢性を向上させるために、訂正検索補強生成(CRAG)を提案します。
具体的には、軽量な検索評価器( retrieval evaluator)を設計して、クエリに対する取得されたドキュメントの全体的な品質を評価し、それに基づいて異なる知識取得アクションをトリガーできるようにします。
静的で限られたコーパスからの取得は、最適でないドキュメントのみを返すことができるため、大規模なウェブ検索が検索結果を拡張するために利用されます。
さらに、取得されたドキュメントに対して、選択的に重要な情報に焦点を当て、それ以外の情報をフィルタリングするための分解して再構成するアルゴリズムが設計されています。
CRAGはプラグアンドプレイであり、さまざまなRAGベースのアプローチとシームレスに組み合わせることができます。
短文と長文の生成タスクをカバーする4つのデータセットでの実験結果は、CRAGがRAGベースのアプローチの性能を大幅に向上させることが示されています。
1 Introduction
大規模言語モデル(LLM)は、ますます注目され、指示を理解し、流暢な言語テキストを生成する驚異的な能力を示しています。
それでも、LLMは必然的に幻覚を示します。
これは、事実の誤りや、取り込んでいるパラメータの知識だけでは生成されるテキストの正確性を確保することができないためです。
以前の研究では、取得した関連知識を組み込み、生成を補完するための取得技術が導入されています。
これは、取得補強生成(RAG)(Lewis et al., 2020)によって具体例として示されています。
このフレームワークでは、モデルへの入力が、外部の知識コーパスから取得された関連ドキュメントを先頭に追加することで拡張されます(Guu et al., 2020)。
RAGはLLMに対する実用的な補完手段として機能しますが、その効果は取得されたドキュメントの関連性と正確性に依存しています(Li et al., 2022; Tan et al., 2022)。
生成が取得された知識に重大に依存することで、モデルの振る舞いや性能に関する重要な懸念が生じます。
特に、取得が失敗したり不正確な結果を返したりする場合のシナリオでは(Shi et al., 2023)。
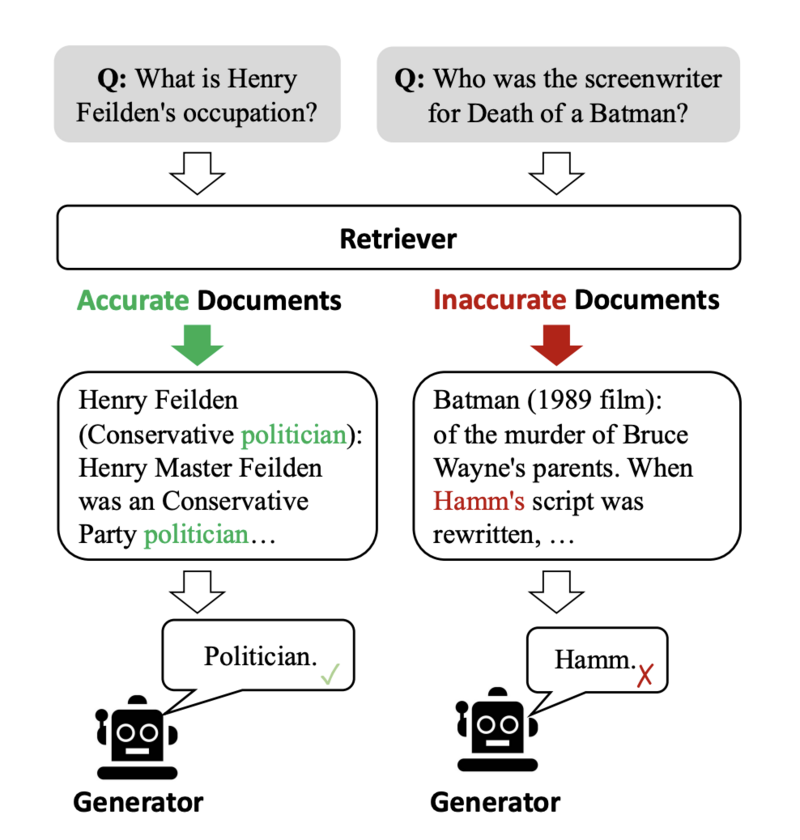
図1に示されているように、品質の低いリトリーバーは大量の無関係な情報を導入しやすく、モデルが正確な知識を獲得するのを妨げ、可能性として誤解を招くことがあり、その結果、幻覚などの問題が発生します(Zhang et al., 2023b)。
ただし、ほとんどの従来のRAGアプローチは、取得されたドキュメントが関連しているかどうかにかかわらず、これらのドキュメントを無差別に組み込みます(Rony et al., 2022)。
さらに、現在の方法では、取得および利用時に完全なドキュメントを参照知識として扱うことが一般的です。
しかし、これらの取得されたドキュメントのテキストのかなりの部分は、生成にとって非本質的であり、RAGに平等に参照され、関与しているべきではありません。
上記の問題に鑑みて、この論文では特に、リトリーバーが不正確な結果を返すシナリオに焦点を当てて研究しています。
リトリーバーの結果を自己修正し、生成を増強するためのドキュメントの利用を向上させるために、Corrective Retrieval-Augmented Generation(CRAG)という手法が提案されています。
軽量な検索評価器(retrieval evaluator)が設計され、クエリに対する取得されたドキュメントの全体的な品質を評価します。
これはRAGの重要な要素であり、取得されたドキュメントの関連性と信頼性を見直し、評価することで、情報の豊富な生成に貢献します。
異なる知識取得アクション(「正しい」、「間違った」、「曖昧な」)をトリガーするために、信頼度が定量化されます。
後者の2つのアクションについては、大規模なウェブ検索が戦略的な拡張として統合されています。
なぜなら、静的で限られたコーパスからの取得は、範囲と多様性の観点で最適でないドキュメントのみを返すためです。
この拡張は、取得された情報のスペクトラムを広げ、最初に取得したドキュメントを補完し、豊かにするために実装されています。
さらに、RAGに役立たない取得されたドキュメントに含まれる冗長な文脈を排除するために、取得および利用プロセス全体にわたって分解して再構成するアルゴリズムが丹念に作成されています。
このアルゴリズムは、取得された情報の精練化を保証し、主要な洞察の抽出を最適化し、非必要な要素の含有を最小限に抑え、取得されたデータの利用を向上させます。
CRAGはプラグアンドプレイであり、実験的にRAG(Lewis et al., 2020)およびSelf-RAG(Asai et al., 2023)に実装され、そのRAGベースのアプローチへの適応性を示すために用いられました。
PopQA(Mallen et al., 2023)、Biography(Min et al., 2023)、Pub Health(Zhang et al., 2023a)、Arc-Challenge(Bhakthavatsalam et al., 2021)の4つのデータセットにおける結果は、CRAGが標準的なRAGおよびSelf-RAGの性能を著しく向上させることができることを示し、短文と長文の生成タスクにわたる一般化能力を示しています。
要約すると、本論文の貢献は以下の3つです:
1)この論文では、リトリーバーが不正確な結果を返すシナリオを研究し、RAGの堅牢性を向上させるための修正戦略を設計する初めての試みを行いました。
2)CRAGというプラグアンドプレイの手法を提案し、自動的な自己修正の能力と取得したドキュメントの効率的な利用を向上させます。
3)実験結果は、CRAGがRAGベースのアプローチに適応し、短文と長文の生成タスクにわたる一般化能力を広範に示しています。
4 CRAG
4.1 モデル推論の概要
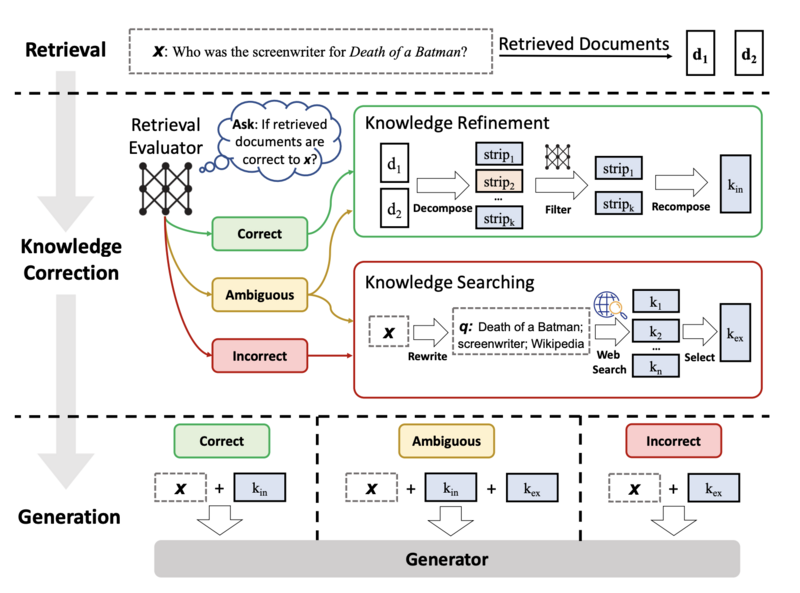
図2:推論時のCRAGの概要。取得評価器が構築され、入力に対する取得されたドキュメントの関連性を評価し、異なる知識取得アクション(「正しい」、「間違った」、「曖昧な」)をトリガーするための信頼度を推定します。
図2とアルゴリズム1は、推論時のCRAGの概要を示しており、生成器の堅牢性を向上させるための修正戦略を設計しています。
入力クエリとリトリーバーから取得されたドキュメントが与えられると、軽量な検索評価器が構築され、取得されたドキュメントの入力クエリへの関連スコアを推定します(セクション4.2)。
計算された関連スコアは、合計3つの信頼度に量子化され、それに応じて対応するアクションがトリガーされます:{正しい、間違った、曖昧な}(セクション4.3)。
正しいアクションがトリガーされた場合、取得されたドキュメントはより正確な知識ストリップに洗練されます。
この洗練操作には、知識の分解、フィルタリング、および再構成が含まれます(セクション4.4)。
間違ったアクションがトリガーされた場合、取得されたドキュメントは破棄されます。
代わりに、ウェブ検索がリソースとして利用され、修正のための補完的な知識源として見なされます(セクション4.5)。
最終的に、システムが正確または不正確な判断を自信を持って行えない場合、両方を組み合わせたソフトなアクションである曖昧なアクションがトリガーされます。
リトリーバル結果を最適化した後、任意の生成モデルが後続して最終結果を生成することができます。
4.2 取得評価器
取得されたドキュメントを利用する前に、取得されたドキュメントが正確かどうかを特定することは自然です。
これは重要です。
なぜなら、無関係な情報や誤解を招く情報をこの方法で除去できるからです。
取得評価器の正確性は、明らかに全体的なシステムの性能を形成する上で重要な役割を果たし、後続のプロセスの結果に影響を与えます。
私たちの目標は、取得されたドキュメントが関連していない場合にそれらを修正することです。
具体的には、T5-large(Raffel et al., 2020)を採用して微調整します。
一般的に、各質問には10件のドキュメントが取得されます。
質問は各単一のドキュメントと連結され、評価者は各質問-ドキュメントのペアに対して個別に関連スコアを予測します。
微調整中、正例のラベルは1であり、負例のラベルは-1です。
推論時に、評価者は各ドキュメントに対して-1から1の関連スコアを付けます。
また、比較のためにChatGPTにリトリーバルの関連性を特定するよう促しましたが、これはセクション5.5で詳しく説明されているように、パフォーマンスが低いです。
Self-RAG(Asai et al., 2023)の批評家モデルと比較して、CRAGで設計された評価者には2つの大きな利点があります。
まず、評価者はT5-largeベース(0.77B)であり、命令を調整したLLaMA-2(7B)と比較して非常に軽量です。
第二に、評価者は追加の人間またはLLM注釈から自由であり、一方、批評家モデルは命令の調整のためにGPT-4注釈付きデータが必要です。
4.3 アクションのトリガー
不適切なドキュメントを修正し、必要に応じて対象のドキュメントを洗練するために、アクションは差別的に実行される必要があります。
各取得されたドキュメントの上記の信頼スコアに基づいて、3つのタイプのアクションが設計され、それに応じてトリガーされます。
上限と下限の閾値が設定されています。
信頼スコアが上限を超える場合、取得されたドキュメントは「正しい」として識別され、下限を下回る場合は「間違った」として識別されます。
それ以外の場合は、「曖昧」が実行されます。このプロセスは、各取得されたドキュメントに個別に実行されます。
ここで、「正しい」と仮定されるのは、少なくとも1つの取得されたドキュメントの信頼度が上限の閾値よりも高い場合です。
そのような場合、取得された結果に関連するドキュメントが存在することを意味します。
関連するドキュメントが見つかったとしても、このドキュメントには必然的にいくつかのノイズのある知識ストリップが含まれています。
このドキュメント内の最も重要な知識ストリップを抽出するために、知識の洗練手法がさらに設計されています。
これについてはセクション4.4で詳しく説明します。
正しくない場合、リトリーバルが想定されます。
全てのリトリーブされた文書の信頼スコアが下限値以下の場合、リトリーブされた全文書が無関係であり、生成に役立たないと見なされます。
したがって、訂正のための新しい知識源を探す必要があります。
ここでは、ウェブ検索がインターネットから検索するために導入されています(セクション4.5で詳述)。
この修正措置は、信頼できる知識を参照できないという厄介な課題を克服するのに役立ちます。
上記の2つの状況を除いて、残りは曖昧な中間行動に割り当てられます。
リトリーブ評価者が判断に自信を持っていないため、正しいものと正しくないものの両方の処理された知識が相補的に組み合わされます。
このような緩和的で柔軟な戦略を実装することは、システムの堅牢性と回復力を強化し、最適な性能を発揮するためのより適応性のあるフレームワークの育成に大きく貢献できます。

4.4 知識の精緻化
取得された関連する文書が与えられた場合、分解して再構成する知識の精緻化手法が設計されています。
まず、各取得された文書はヒューリスティックルールに従って細かく知識のストリップに分割されます。
詳細については付録 B を参照してください。
次に、セクション 4.2 で微調整されたリトリーブ評価者が各知識のストリップの関連性スコアを計算するために使用されます。
これらのスコアに基づいて、無関係な知識のストリップはフィルタリングされ、関連する知識のストリップは順番に連結され、つまり内部知識として再構成されます。
4.5 ウェブ検索
取得された結果がすべて関連性がないと仮定される場合、補完的な外部知識を求めることが非常に重要です。
静的で限られたコーパスからのリトリーブは、範囲と多様性の観点でサブ最適な文書のみを返すことができるため、大規模なウェブ検索(Piktus ら、2021年; Komeili ら、2022年)が RAG の戦略的な拡張として統合されています。
具体的には、ChatGPTによって入力質問がキーワードで構成されたクエリに書き換えられ、検索エンジンの日常的な使用を模倣します。
書き換えられたタスクのプロンプトは付録 A に示されています。
CRAGでは、商用のウェブ検索API2が採用され、各クエリに対して一連のURLリンクが生成されます。
さらに、私たちはURLリンクを使用してウェブページをナビゲートし、そのコンテンツを記録し、セクション4.4と同じ知識の精緻化手法を使用して関連するウェブ知識、つまり外部知識を導出します。
A タスクプロンプト
ウェブ検索クエリとして知識キーワードを生成するためのプロンプトは、表5に示されています。
Extract at most three keywords separated by comma from the following dialogues and questions as queries for the web search, including topic background within dialogues and main intent within questions.
question: What is Henry Feilden's occupation?
query: Henry Feilden, occupation
question: In what city was Billy Carlson born?
query: city, Billy Carlson, born
question: What is the religion of John Gwynn?
query: religion of John Gwynn
question: What sport does Kiribati men's national
basketball team play?
query: sport, Kiribati men's national basketball team play
question: [question]
query:
表5: GPT-3.5 Turboに対する知識キーワードをウェブ検索クエリとして生成するためのフューショットプロンプト。
ChatGPTを評価者として指示するプロンプトは、それぞれ表6、表7、表8に示されていました。
Given a question, does the following document have exact information to answer the question? Answer yes or no only.
Question: [question]
Document: [document]
表6: 評価者としてのGPT-3.5 Turboへの直接プロンプト。
Given a question, does the following document have exact information to answer the question? Question: [question] Document: [document] Think Step by step, and answer with yes or no only.表7: Chain-of-Thoughtを評価者としてGPT-3.5 Turboへのプロンプト。
Given a question, does the following document have exact information to answer the question? Answer yes or no only. Question: In what city was Abraham Raimbach born? Document: Bancroft was born on November 25, 1839 in New Ipswich, New Hampshire to James Bancroft and Sarah Kimball. At an early age he was cared for by Mr. and Mrs. Patch of Ashby, Massachusetts, the neighboring town. While not legally adopted, they named him Cecil Franklin Patch Bancroft, adding Franklin Patch after the son Mr. and Mrs. Patch had who recently died. He attended public schools in Ashby as well as the Appleton Academy in New Ipswich. He entered Dartmouth College in 1856 at the age of sixteen and graduated in 1860 near the top of his class. Bancroft continued his education as he began his career in teaching. He took classes at the Union Theological Seminary in New York City during the 1864- 65 academic year. While there he was a member of the United States Christian Commission, traveling to support soldiers during the Civil War. He then transferred to the Andover Theological Seminary where he would graduate in 1867. Answer: No. Question: In what country is Wilcza Jama, Sokółka County? Document: Wilcza Jama is a village in the administrative district of Gmina Sokółka, within Sokółka County, Podlaskie Voivodeship, in north-eastern Poland, close to the border with Belarus. Answer: Yes. Question: What sport does 2004 Legg Mason Tennis Classic play? Document: The 2004 Legg Mason Tenis Classic was the 36th edition of this tennis tournament and was played on outdoor hard courts. The tournament was part of the International Series of the 2004 ATP Tour. It was held at the William H.G. FitzGerald Tennis Center in Washington, D.C. from August 16 through August 22, 2004. Answer: Yes. Question: Who is the author of Skin? Document: The Skin We're In: A Year of Black Resistance and Power is a book by Desmond Cole published by Doubleday Canada in 2020. The Skin We're In describes the struggle against racism in Canada during the year 2017, chronicling Cole's role as an anti-racist activist and the impact of systemic racism in Canadian society. Among the events it discusses are the aftermath of the assault of Dafonte Miller in late 2016 and Canada 150. The work argues that Canada is not immune to the anti-Black racism that characterizes American society. Due to an error by the publisher, the initial printing of the book's cover did not include word Blackïn the subtitle. The mistake was later ¨ corrected. The book won the Toronto Book Award for 2020. In 2021, the book was nominated for the Shaughnessy Cohen Prize for Political Writing. Answer: No. Question: [question] Document: [document] Answer:Table 8: 評価者としてのGPT-3.5 Turboへのフューショットプロンプト。
B 実装の詳細
評価者:
我々は、軽量なT5-large(Raffel ら、2020年)の事前学習済みモデルに基づいて、タスク固有のリトリーバル評価者モデルを微調整しました。
そのパラメータサイズは、Self-RAGやPaLM(Chowdhery ら、2023年; Anil ら、2023年)シリーズ、GPTシリーズ(Brown ら、2020年; Ouyang ら、2022年; OpenAI、2023年)などの最新のLLM(Large Language Models)よりもはるかに小さくなっています。
三つのアクションのうちの一つをトリガーするための二つの信頼閾値は、トレーニングセットの経験に基づいて計算され、偽陽性の罰則を最大化するために使用されました。
最大化関数は次のようにまとめることができます:
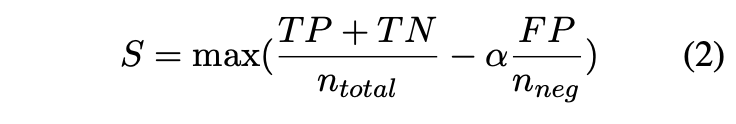
ここで、ntotalはすべてのサンプルを、nnegはすべての不正解と判断されたサンプルを意味し、αはこの実験で1に設定されています。訓練された評価者は極性のあるスコアを予測する傾向があるため、最初の閾値はしばしば0.5前後に設定されます。例えば、PopQAでは0.59、PubQAでは0.5です。そして、第二の閾値は-0.9前後に設定されます。
内部知識:
細かいリトリーブ結果を得るために、取得された結果を内部ストリップに分割しました。
取得された結果が1〜2文程度の短い場合、それを個々のストリップと見なし、それ以外の場合はリトリーブ文書をより小さな単位に分割する必要があります。
通常、これらの単位はいくつかの文で構成されています。
スケールは独立した情報の一部を含むものと見なされ、フィルタリングはセグメントに基づいて行われます。
私たちは再び知識ストリップのフィルタリングに評価者を直接採用し、トップ-kを5に設定し、フィルターの閾値を-0.5に設定しました。
外部知識:
Google Search APIを使用して関連するURLを検索し、トップ-kを5に設定し、Wikipediaのページが優先的に追加されます。
検索されたウェブページは一般的にHTMLファイルの形式であり、コンテンツは
や
のような特殊トークンで分割されます。したがって、知識の精緻化のような追加のセグメンテーションは必要ありません。
関連する知識段落は、内部知識と同様に、評価者を使用して直接選択することができます。
生成器:
CRAGはプラグアンドプレイの方法であるため、RAGで利用可能なすべての生成モデルが、私たちのアプローチにも適合します。
比較のためのベースラインとの一貫性を保つために、生成にはLLaMA2(Touvronら、2023b)を採用しました。
まず、huggingfaceからLLaMA2-hf7bを導入して応答を生成しました。
Self-RAG(Asaiら、2023年)がLLaMA2を微調整し、いくつかのタスクで新たな最高性能を達成したため、私たちは彼らの作業と一貫性を保ち、特定の改善を研究するために、起動されたモデルであるSelfRAG-LLaMA2-7bを新しい生成器としてさらに利用しました。
Self-CRAG:
私たちのプラグアンドプレイのアプローチが他の同時進行研究で利用できることを示すために、私たちは特に自己-RAG(Asaiら、2023年)フレームワークに私たちのCRAGを挿入するよう設計し、それをSelf-CRAGと名付けました。
Self-RAGは、生成に参照するためのリトリーブされた文書を決定するための批評家モデルを導入した高度なRAGアプローチです。
どのアクションをトリガーするかを決定するための私たちの要求に合致しており、したがって、Self-RAGのリトリーブされたアイテムを、私たちの処理された内部知識(Correct用)、外部知識(Incorrect用)、および組み合わせた知識(Ambiguous用)で置き換えました。
Comments