全日本空輸(ANA/NH)は、3月22日午前8時20分ごろ発生した国内線予約システム「エイブル」の障害について、午後8時10分ごろ復旧したことを明らかにした。この影響で、22日はANAの国内線だけで146便が欠航し、約1万8200人に影響が出た。遅延便も391便にのぼり、約5万3700人に影響が及んだ。
ANAによると、システムを構成する4台のサーバーのうち、22日午前3時44分に1台が停止。その後午前8時15分には新たに2台が停止し、午前8時22分には残る1台も停止した。この時に、サーバーの保守作業などは行われていなかったという。
その後1台を再起動し、2台目の再起動作業に取りかかったところ、正常に動作しなかった。このため、再起動に成功した1台のみ稼働させ、空港で搭乗手続きなどに使う「空港系システム」を午前11時30分ごろ復旧させた。
同社ではバックアップ用システムも用意していたが、切り替えに1時間程度掛かることから、朝の混雑時間帯の混乱を避けるため、再起動した1台を中心に復旧作業を進めた。ウェブサイト上での国内線予約や決済、座席指定、チェックインなどに使う「予約販売系システム」は、午後8時10分ごろ復旧した。
ANAでは、4台のサーバー間で顧客データベースを同期させるシステムに障害が発生したとみて、原因究明を急いでいる。現時点では、ハードウェアとソフトウェアのどちらに問題があったかなど、特定に至っていない。
現在の国内線予約システムは、2013年7月に稼働。今回の障害発生まで、システムが停止するトラブルは起きていないという。通常期の予約販売は1台のサーバーで対応できるが、繁忙期は2台分の処理能力が必要だとして、その2倍にあたる4台でシステムを構築した。
フェイルオーバー設計は気になります。
「22日午前3時44分に1台が停止。その後午前8時15分には新たに2台が停止し、午前8時22分には残る1台も停止した」。同時の4台のHW故障が考えにくいので、ハードウェアよりソフトウェアの問題ですね。通常はDBサーバは業務アプリケーションが走らないから、トランザクション周りのDBソフトウェアの問題ですかな?データ欠損なのか設定なのかバグなのかなんとも言えないですけど。
「通常期の予約販売は1台のサーバーで対応できるが、繁忙期は2台分の処理能力が必要だ」。ピーク時に2台サーバでも大丈夫だということ。4台体制は、4台オンライン+4台スタンバイですかね?「切り替えに1時間程度掛かることから」なので、ホットスタンバイではない。であると、ホットスタンバイにしないといけない。切り替えは手動前提だとこういうことなってますね。
今の会社は約18年前からNOSQLを使ってましたが(当時NOSQLという単語がなかったと思う)、エンタプライス系は通常RDBMSですよね。スケールアウトしにくいけど、実績がわかるので急な大量アクセスがないでしょ。ですので今の構成で障害時の自動切り替えやテーブルの物理分割などは有効かもしれません。疎結合のスキーマにして、結合は別マシンで、別の非同期処理でやるのがありかもしれません。
続報があればまた更新したいと思います。
------ update 2016/03/24 17:20 ------
同社は1台ずつ復旧させようとしたが、2台目を立ち上げると、1台目がダウンする状況が繰り返された。こうしたことから、端末間で情報を共有する機能に問題があり、不具合が連鎖した可能性が高いと判断した。最初の1台がダウンした原因は不明という。
データ欠損の可能性が高いですね。
全日本空輸株式会社の基幹系システムである,国内線旅客システムがオープンプラッ トフォーム環境にて 2013 年 2 月に稼働した.旧システムはメインフレームの高い可用性と 信頼性に支えられ,30 年以上稼働し続けてきた.オープン系技術の台頭から久しく,IT コ ストの抑制からオープンプラットフォームへの移行が情報系システムを中心に進められてき たが,基幹系システムのオープンプラットフォーム移行には大きなリスクを伴う.
本稿は,今回の国内線旅客システムの移行において,メインフレームと同等の高いサービ スレベルをいかに実現したかについて記載する.
DBサーバ:HP Superdome 4 ノード構成、OS(HP-UX 11i v3)
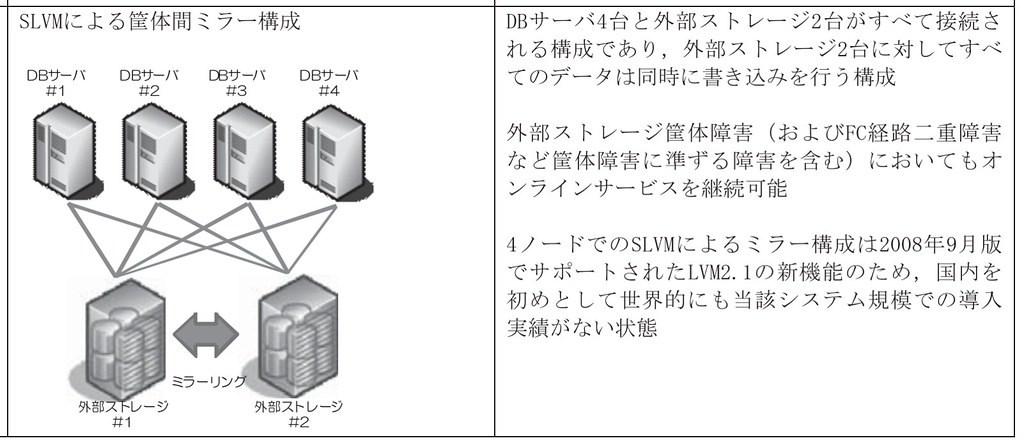
「本構成は,オープンシステムにおいては世 界初となる外部ストレージ筐体間ミラー構成であり,本番稼働後も安定的に稼働している.」
とのことですので、今回は初めての大規模障害ですかね。
さらに、ANACoreというシステムについて、以前使っていたMQの非同期処理をやめて、オラクルを信頼(依頼)する形に変更を行いました。
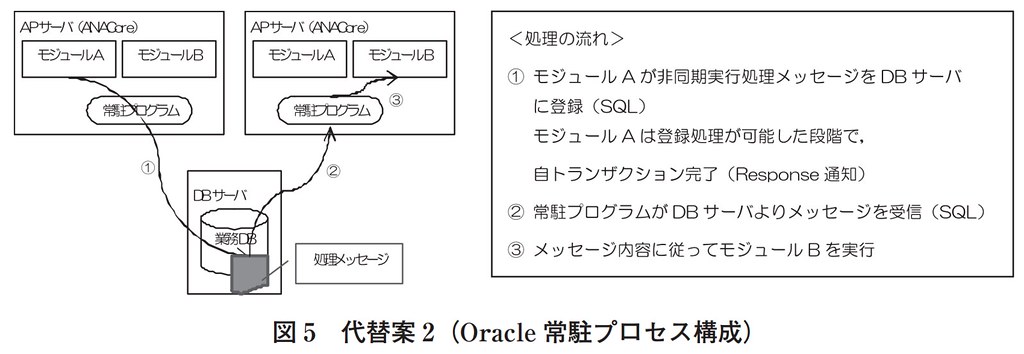
「業務トランザクションに対して SPOF をすべて排除するというシス テム化方針を満たすために,AirCore パッケージが採用しているアーキテクチャを崩すことと なったが,結果として数十秒の業務停止が発生するという可能性を排除した構成とすることが できた.」
MQをやめて、オラクルのテーブルを利用すればシステム構成がシンプルになり、開発コストも削減できたでしょうね。しかしアーキテクチャの脆弱性が残ったままですから、結局オラクルがSPOFになって、今回の障害につながったわけですかね。。あくまで想像ですけど、あそこのDBが個別のHWを使えばいいのに。
システム設計についてはいろいろな評価ポイントがありますが、結局のところ、障害につながるかどうかは表面的な評価項目ではわからないでしょ。
とても言葉や文章では表現できないが、感覚的に「ここがヤバイ」というのが自分の経験です。しかし、SPOF、疎結合などを徹底的にやれば、Linux/FreeBSDベースのPCサーバでも数億アクセス/日のシステムが安全運営できたからね。
------ update 2016/03/30 21:20 ------
全日空は30日、今月22日に起きた国内線のシステムトラブルについて、システムを管理するサーバー4基をつなぐ中継機の集積回路(IC)の故障が原因だったと発表した。
中継機はサーバー間で情報を共有する機器。故障すれば信号を発信して予備機に自動で切り替わるが、こうした機能が作動しなかった。このため原因特定が遅れ、影響が広がったという。
中継機とは?上記のUNISYSのシステム構成図にないものですから、ネットワークレイヤーのスイッチ?謎ですね。
Comments