AI Agentの技術進歩より、開発のAI化も「AI支援」から「AI駆動」へと進化してきた。
特にClaude Codeの出現で、設計・開発・テストなどの開発全工程にAIの実用性は格段に向上した。
ですので、最近よく耳にする開発方法論をまとめてみた。
AI Assisted Development (AIAD)
概要:
人間がコードやアプリケーションの作成という主要な役割を担う AIアシスタントはオートコンプリート機能、チャットによるQ&A、コードの説明、ドキュメント自動作成、テストケース作成など
主要ツール: Github CoPilot
AI Driven Development (AIDD)
概要:
コード生成、バグ検出、ドキュメント作成といったタスクの大部分を自動化します。 AIがコードやアプリケーションの作成という主要な役割を担います。
主要ツール: Codex Claude Code
生成AIの企業活用について、多くの記事が「生産性向上」「コスト削減」「業務効率化」といった抽象的なメリットを語ります。
しかし、実際に経営の現場で日々判断を下している私たちが本当に知りたいのは、そうしたバズワードではありません。
経営者として直面している具体的な課題
--
ベテラン社員の引退による知識の喪失、
市場変化への対応の遅れ、
後継者育成の停滞、
意思決定に必要な情報の散在
--
こうした現実の「痛み」に対して、生成AIがどのように寄り添い、伴走してくれるのか。
それを知りたいのです。
本記事では、K2A(Knowledge-to-AI)フレームワークという実践的なアプローチを通じて、経営者が一年間かけて4つの本質的課題に段階的に取り組み、組織のナレッジを可視化・継承・発展させていく具体的な道筋を提示します。
経営者に寄り添う生成AI活用戦略デジタル教材も提供しているので、ぜひご覧ください。
4Aモデル(AI Agent Application Architecture)は、小生が提唱するLLMベースのAIエージェントアプリケーションを迅速かつ拡張性高く構築するためのリファレンスアーキテクチャです。以下の6つのレイヤーで構成され、エンタープライズ用途に対応可能なセキュリティ・柔軟性・観測性を備えています:

User Interface Layer
Gateway Layer
Orchestrator / Reasoning Layer
MCP Server / Tool Layer
Data / API Layer
Context / Memory Layer
話題中のmanus.imを使ってChatgpt Enterpriseに対して検討してもらったので結果共有します。
元々の質問
chatgpt enterpriseの機能を知りたいです。特に3万人の企業で使う予定ですので、セキュリティ、ガバナンス、作業効率などの観点でどのくらいメリットがあるのか知りたい。
ここにいろんなマニュアルがあります
https://help.openai.com/en/collections/5688074-chatgpt-enterprise
15分後1回目の調査結果を頂きました。
SSO, SCIM, and User Management SSO Overview
SSO は、エンタープライズおよび教育機関向けの顧客のみが利用可能です。
背景のアーキテクチャと用語
現在、ChatGPT および API プラットフォームの両方で、SAML 認証を通じた SSO がサポートされています。
•ワークスペース:ChatGPT のインスタンスを指します。
•組織(Organization):API プラットフォームのインスタンスを指します。
•アイデンティティプロバイダー(IdP):デジタル ID を管理するために使用するサービスを指します。当社は、SAML をサポートするすべての IdP との接続をサポートしています。代表的な IdP には以下が含まれます:Okta,Azure Active Directory/Entra ID, Google Workspace
現在、各 ChatGPT ワークスペースには、それに対応するプラットフォーム組織が関連付けられています。
つまり、エンタープライズ プラットフォームの「一般」ページにある 組織 ID(org-id) は、エンタープライズ ChatGPT ワークスペースに関連付けられている 組織 ID(org-id) と同じです。
そのため、ワークスペースと組織は同じ認証レイヤーを共有しています。
What is ChatGPT Enterprise?
公式ドキュメントの更新時間は2024年6月のままですので、あまり機能更新していないかもしれません。
ChatGPT Enterpriseとは?
ChatGPT Enterpriseは、企業向けのセキュリティとプライバシーを備えたサブスクリプションプランです。無制限の高速GPT-4oアクセス、長い入力を処理できる拡張コンテキストウィンドウ、高度なデータ分析機能、カスタマイズオプションなど、さまざまな機能を提供します。
自社でChatGPT Enterpriseを利用するには?
ChatGPT Enterpriseを導入したい場合は、営業チームにお問い合わせください。「どの製品やサービスに興味がありますか?」の項目で「ChatGPT Enterprise」を選択してください。
ChatGPT Enterpriseのセキュリティとプライバシー管理について
ChatGPT Enterpriseでは、ビジネスデータをユーザー自身が所有・管理できます。お客様のビジネスデータや会話を学習に使用することはなく、モデルも使用履歴から学習しません。また、ChatGPT EnterpriseはSOC2準拠であり、すべての会話は送信時および保存時に暗号化されます。
さらに、新しい管理コンソールでは、チームメンバーの管理、ドメイン認証、SSO(シングルサインオン)、利用状況のインサイト機能を提供し、エンタープライズ環境での大規模導入を可能にします。
詳しくは、プライバシーページやTrust Portalをご覧ください。追加のご質問がある場合は、営業チームまでお問い合わせください。
ChatGPT Enterpriseのその他の特徴
ChatGPT Enterpriseでは、以下の点が一般ユーザー向けプランと異なります:
• 無制限のGPT-4 Turboアクセス(使用制限なし)
• 高速なパフォーマンス
• 高度なデータ分析機能の無制限利用(旧Code Interpreter)
• 共有可能なチャットテンプレート(企業内のワークフロー構築や共同作業に活用可能)
ChatGPT Enterpriseのサポートを受けるには?
問題が発生した場合は、ヘルプセンターのチャットツールを使ってサポートチームにお問い合わせください。迅速に対応いたします!
先月、銀座をぶらぶらしていたとき、偶然渡邊版画店で100年以上前に制作された版画作品「Gateway To Ming Tombs」を見つけました。
店主(創業者・渡邊庄三郎氏の孫にあたる渡邊章一郎氏)によると、
この作品の画家バートレットはイギリス人で、中華民国初期に中国を訪れた際に油彩画または水彩画として描いたものだそうです。
その後、彼は東京に渡り、渡邊版画と協力して一連の版画を制作しました。その中の一つがこの「Gateway To Ming Tombs」です。
この作品はバートレットの個人注文によって制作されたため、市場にほとんど流通せず、現存するものは非常に稀少です。
そのときはあまり深く考えず、「これは珍しい作品だ」と思い、高額で購入しました。
帰宅後、さらにネットで調べた情報をここにまとめておきます。



Corrective Retrieval Augmented Generation
Abstract
大規模言語モデル(LLM)は、生成されるテキストの正確性を完全に確保することができないため、必然的に幻覚を示します。(情報を取り込んでいるパラメータの知識だけでは。)
検索補強型生成(RAG)はLLMを補完する実用的な手段ですが、取得されたドキュメントの関連性に大きく依存しており、検索が誤った場合にモデルがどのように振る舞うかという懸念があります。
このため、私たちは生成の堅牢性を向上させるために、訂正検索補強生成(CRAG)を提案します。
具体的には、軽量な検索評価器( retrieval evaluator)を設計して、クエリに対する取得されたドキュメントの全体的な品質を評価し、それに基づいて異なる知識取得アクションをトリガーできるようにします。
静的で限られたコーパスからの取得は、最適でないドキュメントのみを返すことができるため、大規模なウェブ検索が検索結果を拡張するために利用されます。
さらに、取得されたドキュメントに対して、選択的に重要な情報に焦点を当て、それ以外の情報をフィルタリングするための分解して再構成するアルゴリズムが設計されています。
CRAGはプラグアンドプレイであり、さまざまなRAGベースのアプローチとシームレスに組み合わせることができます。
短文と長文の生成タスクをカバーする4つのデータセットでの実験結果は、CRAGがRAGベースのアプローチの性能を大幅に向上させることが示されています。
RAGは本当に熱い。会社で検証環境を提供したら使いたい要望が殺到している。ある部門の試算では年間10数億円の利益貢献。これでちゃんとPJ化しないね。
ただ体系的に検索品質を評価するためにどうすれば良いのか課題なのでこちらを参考になった。
Best Practices for LLM Evaluation of RAG Applications
長い文章のため、ChatGPTで下記Promptで訳してもらった:
「あなたはプロの日英翻訳専門家。質問者に質問して、質問者からの英語を日本語に訳してください。翻訳のプロセスは2段階でお願いします。まず直訳して、それから直訳の結果に対して、ネイティブ日本語者から見ても自然な日本語に再度訳直してください。」
---
チャットボットは、大規模な言語モデル(LLM)の強力なチャットと推論能力を活用するための最も普及したユースケースです。
Retrieval augmented generation (RAG) アーキテクチャは、ナレッジベース(ベクトルストアを介した)の利点と生成モデル(例:GPT-3.5およびGPT-4)を組み合わせることで、幻覚を減らし、最新の情報を維持し、特定のドメインの知識を活用するための業界標準となりつつあります。
しかし、チャットボットの応答の品質を評価することは今日も未解決の問題です。
業界標準が定義されていないため、組織は人間による評価(ラベリング)に頼る必要がありますが、これは時間がかかり、スケーリングが難しいです。
私たちは、実践に理論を適用して、LLMの自動評価のベストプラクティスを形成し、RAGアプリケーションを迅速かつ自信を持ってプロダクションに展開できるよう支援しました。
このブログは、Databricksで実施している一連の調査の最初を表しており、LLMの評価に関する学びを提供することを目指しています。
この投稿でのすべての研究は、Databricksのシニアソフトウェアエンジニアであり、Databricks Documentation AI Assistantの作成者であるQuinn Lengによって実施されました。
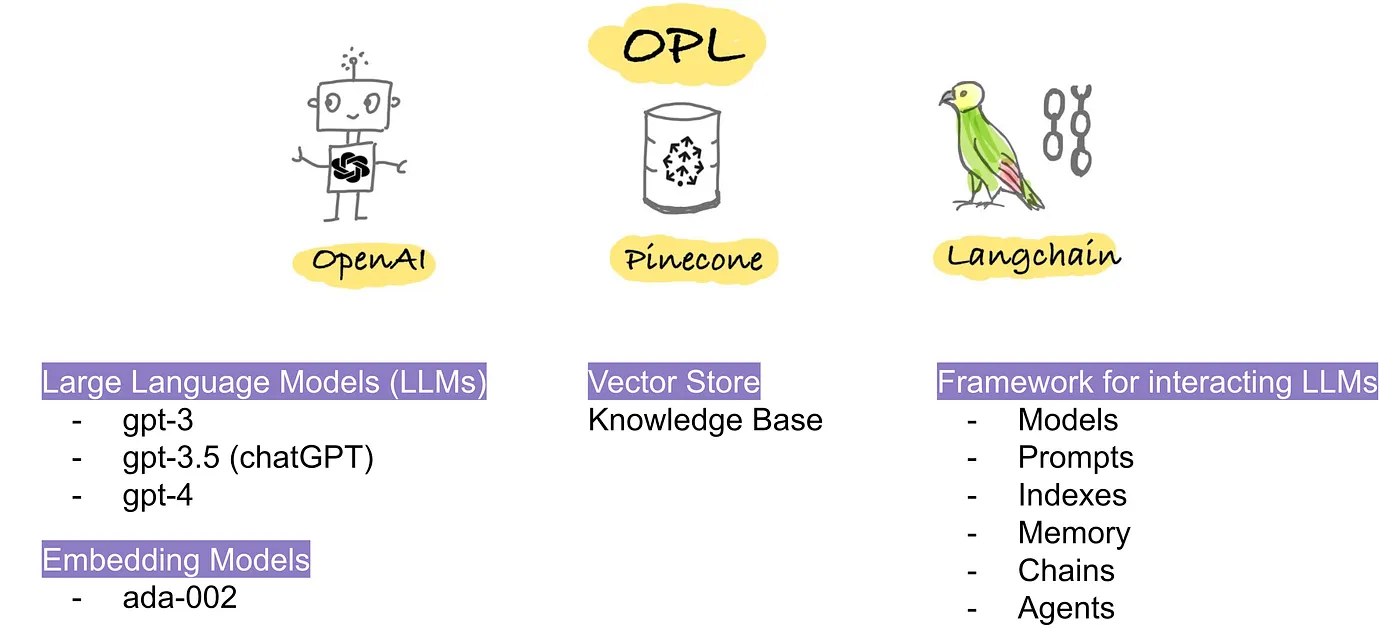
Building LLMs-Powered Apps with OPL Stack
OPL stands for OpenAI, Pinecone, and Langchain
OpenAI:
- 強力なLLM(例:chatGPTとgpt-4)へのAPIアクセスを提供します。
- テキストを埋め込みに変換するための埋め込みモデルを提供します。
Pinecone:
- 埋め込みベクトルの保存、意味的類似性の比較、高速な検索を提供します。
Langchain:
- 6つのモジュール(モデル、プロンプト、インデックス、メモリ、チェーン、エージェント)から構成されています。
- モデルは埋め込みモデル、チャットモデル、LLMなどの柔軟性を提供します。これにはOpenAIの提供するものに限らず、Hugging FaceのBLOOMやFLAN-T5などの他のモデルも使用できます。
- メモリ:チャットボットが過去の会話を記憶するためのさまざまな方法があります。私の経験から言うと、エンティティメモリはうまく動作し効率的です。
- チェーン:Langchainに初めて触れる場合、チェーンは素晴らしい出発点です。ユーザーの入力を処理し、LLMモデルを選択し、プロンプトテンプレートを適用し、知識ベースから関連するコンテキストを検索するためのパイプラインのような構造を持っています。